Nigerian universities have long struggled to identify, before matriculation, which applicants are likely to become disciplinary problems on campus. Existing screening procedures are largely manual and reactive — problems surface after enrolment rather than at the gate. To close this gap, we built and tested a Multi-Layer Perceptron classifier that assigns each applicant a probabilistic risk score at the point of admission, giving institutional officers an evidence-based basis for early counselling and targeted resource deployment, well before misconduct occurs. Working with real student records was not feasible. Nigeria's data protection obligations impose strict constraints on profiling, and authentic admission data from universities was unavailable for this research. We therefore generated 5,000 synthetic applicant profiles using a Conditional Tabular GAN, a method purpose-built for datasets that mix continuous, ordinal, and categorical variables. Three statistical tests — the Kolmogorov–Smirnov statistic, Wasserstein distance, and Jensen–Shannon divergence — confirmed that the synthetic profiles reproduced the structural properties of realistic admission populations with high fidelity. Under five-fold stratified cross-validation, the MLP returned an accuracy of 0.841 ± 0.018, F1-score of 0.812 ± 0.021, and AUC-ROC of 0.891 ± 0.014, outperforming Logistic Regression, Random Forest, SVM, and XGBoost across all reported metrics. Two findings deserve particular attention. First, SHAP attribution analysis singled out prior disciplinary record and JAMB score as the variables driving predictions most strongly — a result with direct implications for what admissions officers should scrutinize. Second, the model treated applicants from different geopolitical zones unequally; an EOD of 0.078 across zones exceeded acceptable thresholds. Fairness-regularized retraining brought that Figure down to 0.043 with less than one percentage point of accuracy lost. To prevent the system from operating as a black box, a three-tier human-in-the-loop review protocol is proposed, and the entire deployment framework is mapped against Nigeria's National Data Protection Regulation and Data Protection Impact Assessment requirements.
| Published in | International Journal of Engineering Management (Volume 10, Issue 1) |
| DOI | 10.11648/j.ijem.20261001.11 |
| Page(s) | 1-13 |
| Creative Commons |
This is an Open Access article, distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution and reproduction in any medium or format, provided the original work is properly cited. |
| Copyright |
Copyright © The Author(s), 2026. Published by Science Publishing Group |
Multi-layer Perceptron, Algorithmic Fairness, Synthetic Data, CTGAN, SHAP Explainability
Category | Feature | Type | Description |
|---|---|---|---|
Academic | JAMB_score | Continuous | Standardized entry examination score |
Academic | WAEC_aggregate | Continuous | Standardized secondary-school aggregate score |
Academic | Num_sittings | Ordinal | Number of examination sittings |
Behavioral | Prior_discipline | Binary | Prior recorded disciplinary incident indicator |
Behavioral | Substance_use | Binary | Self-reported substance-use indicator |
Behavioral | Peer_conflict | Ordinal | Peer-conflict history scale |
Behavioral | Extracurricular | Binary | Structured extracurricular participation indicator |
Demographic | Age | Continuous | Applicant age |
Demographic | Gender | Binary | Self-identified gender |
Demographic | Geopolitical_zone | Categorical | Regional zone category (6 levels) |
Regional | Crime_index | Continuous | Regional risk proxy from contextual signals |
Regional | Urbanization_index | Continuous | Regional urbanization proxy |
Regional | Unemployment_rate | Continuous | Regional unemployment proxy |
Regional | School_density | Continuous | Regional school-density proxy |
INPUT: D = {(xᵢ, yᵢ)} i=1.. N (N=5000, d=22), K=5 folds, α=0.001, patience=10 |
OUTPUT: Trained model f*, performance metrics, SHAP attributions |
PREPROCESSING (leakage-safe, per fold): |
Dₜᵣₐᵢₙ, Dₜₑₛₜ ← StratifiedKFold. split(D) |
μ, σ ← compute mean & std on Dₜᵣₐᵢₙ continuous features |
X_train_scaled ← z-score(Dₜᵣₐᵢₙ, μ, σ); X_test_scaled ← z-score(Dₜₑₛₜ, μ, σ) |
X_train_bal, y_train_bal ← SMOTE(X_train_scaled, y_train) |
Architecture: |
Input(22) → Dense(64, ReLU) → BatchNorm → Dropout(0.3) |
→ Dense(32, ReLU) → BatchNorm → Dropout(0.3) |
→ Dense(1, Sigmoid) [output: p = Pr(y=1|x)] |
Training Loop: |
optimizer ← Adam(lr=α); loss ← BinaryCrossEntropy |
for epoch = 1 to MaxEpoch: |
loss_train ← forward(X_train_bal) + backprop |
loss_val ← forward(X_val) [no grad] |
if loss_val not improved for `patience` epochs: BREAK [early stop] |
Evaluation (per fold): |
ŷ ← f(X_test_scaled) > 0.5; Record ACC, P, R, F1, AUC-ROC |
Compute DPD, EOD, PED over gender and geopolitical zone groups |
SHAP_global ← mean|SHAP(f, X_test_scaled)|; SHAP_local ← waterfall plots |
REPORT: Mean ± SD over K=5 folds for all metrics |
Feature | Type | KS Statistic | p-value | W-dist / JSD | Interpretation |
|---|---|---|---|---|---|
JAMB_score | Continuous | 0.042 | 0.312 | W=0.019 | No significant difference |
WAEC_aggregate | Continuous | 0.038 | 0.401 | W=0.015 | No significant difference |
Age | Continuous | 0.051 | 0.198 | W=0.022 | No significant difference |
Crime_index | Continuous | 0.067 | 0.089 | W=0.031 | No significant difference |
Urbanization_index | Continuous | 0.045 | 0.278 | W=0.018 | No significant difference |
Unemployment_rate | Continuous | 0.058 | 0.142 | W=0.026 | No significant difference |
School_density | Continuous | 0.039 | 0.388 | W=0.014 | No significant difference |
Gender | Categorical | — | — | JSD=0.008 | Excellent fidelity |
Geopolitical_zone | Categorical | — | — | JSD=0.021 | Excellent fidelity |
Correlation RMSE | — | 0.034 | — | — | Good joint structure preservation |
Model | Accuracy | AUC-ROC | Precision | Recall | F1-Score |
|---|---|---|---|---|---|
Logistic Regression | 0.763 ± 0.022 | 0.821 ± 0.019 | 0.734 ± 0.028 | 0.712 ± 0.031 | 0.723 ± 0.025 |
Random Forest | 0.812 ± 0.019 | 0.868 ± 0.016 | 0.789 ± 0.024 | 0.778 ± 0.027 | 0.783 ± 0.022 |
SVM (RBF) | 0.798 ± 0.021 | 0.854 ± 0.018 | 0.771 ± 0.026 | 0.756 ± 0.029 | 0.763 ± 0.024 |
XGBoost | 0.829 ± 0.017 | 0.882 ± 0.015 | 0.804 ± 0.022 | 0.791 ± 0.025 | 0.797 ± 0.020 |
MLP (Proposed)* | 0.841 ± 0.018 | 0.891 ± 0.014 | 0.818 ± 0.023 | 0.807 ± 0.026 | 0.812 ± 0.021 |
Feature Subset | Accuracy | AUC-ROC | F1-Score |
|---|---|---|---|
Academic only | 0.742 | 0.798 | 0.721 |
Behavioral only | 0.768 | 0.831 | 0.749 |
Demographic only | 0.621 | 0.673 | 0.598 |
Regional only | 0.654 | 0.702 | 0.631 |
Academic + Behavioral | 0.814 | 0.869 | 0.796 |
All features (Full Model) | 0.841 | 0.891 | 0.812 |
Protected Attribute | DPD | EOD | PED |
|---|---|---|---|
Gender (Male vs Female) | 0.032 | 0.041 | 0.028 |
Geopolitical Zone (max across 6 zones) | 0.071 | 0.078 | 0.063 |
Strategy | Accuracy | F1-Score | EOD (Zone) | DPD (Zone) |
|---|---|---|---|---|
MLP-Base (no mitigation) | 0.841 ± 0.018 | 0.812 ± 0.021 | 0.078 ± 0.009 | 0.071 ± 0.008 |
Post-processing (threshold adj.) | 0.826 ± 0.020 | 0.798 ± 0.023 | 0.051 ± 0.011 | 0.044 ± 0.010 |
In-processing (EOD loss penalty) | 0.833 ± 0.019 | 0.804 ± 0.022 | 0.043 ± 0.010 | 0.038 ± 0.009 |
Rank | Feature | Mean |SHAP| | Category & Interpretation |
|---|---|---|---|
1 | JAMB_score | 0.142 | Academic — strongest predictor; reflects cognitive preparedness |
2 | Prior_discipline | 0.128 | Behavioral — direct behavioral risk signal |
3 | WAEC_aggregate | 0.109 | Academic — secondary entry qualification |
4 | Peer_conflict | 0.097 | Behavioral — aggregated social conduct scale |
5 | Substance_use | 0.083 | Behavioral — self-reported risk indicator |
6 | Crime_index | 0.071 | Regional — proxy for structural environmental risk (monitor for proxy bias) |
7 | Age | 0.058 | Demographic — marginal effect; caution re. age discrimination |
8 | Extracurricular | 0.052 | Behavioral — protective factor (negative attribution) |
9 | Unemployment_rate | 0.044 | Regional — contextual stressor proxy |
10 | Num_sittings | 0.039 | Academic — marginal engagement signal |
MLP | Multi Layer Perceptron |
AUC-ROC | Area Under the Receiver Operating Characteristic Curve |
CTGAN | Conditional Tabular Generative Adversarial Network |
DPIA | Data Protection Impact Assessment |
DPD | Demographic Parity Difference |
EDM | Educational Data Mining |
HTIL | Human-in-the-Loop |
JAMB | Joint Admissions and Matriculation Board |
JSD | Jensen–Shannon Divergence |
KS | Kolmogorov–Smirnov |
LIME | Local Interpretable Model-agnostic Explanations |
LMS | Learning Management System |
NDPR | Nigeria Data Protection Regulation |
PED | Predictive Equality Difference |
RBF | Radial Basis Function |
SHAP | SHapley Additive exPlanations |
SMOTE | Synthetic Minority Over-sampling Technique |
SVM | Support Vector Machine |
WAEC | West African Examinations Council |
| [1] | Mourabit IE, Jai-Andaloussi S, Abghour N (2021) Educational Data Mining Techniques for Detecting Undesirable Students' Behaviors and Predicting Students' Performance: A Comparative Study. Advances on Smart and Soft Computing. |
| [2] | Martins MV, Tolledo D, Machado J, et al (2021) Early Prediction of student's Performance in Higher Education: A Case Study. WorldCIST. |
| [3] | Ngulube P, Ncube MM (2025) Predicting Academic Success and Identifying At-Risk Students: A Systematic Review. Educational Administration: Theory and Practice. |
| [4] | Toirova G, Kosimov A, Fayziyeva M, et al (2025) Machine Learning Models for Identifying at-Risk Students: Applications and Challenges in Higher Education. ICFTS 2025. |
| [5] | Barnes EE, Hutson PJ, Perry PK. Ethical Imperatives and Challenges: Review of the Use of Machine Learning for Predictive Analytics in Higher Education. Semantic Scholar. |
| [6] |
Conditional Tabular GAN (CTGAN) - Clover documentation.
https://crchum-citadel.github.io/clover-doc/userguide/generators/ctgan.html |
| [7] | C SK, Anthraper MG, Sanjaykumar K, et al (2025) Synthetic Data Generation Using CTGAN with Agentic Workflows and Retrieval-Augmented Generation. ICAIR. |
| [8] | Won D-H, Shin K-S, Youm S (2026) Synthetic Data Augmentation for Imbalanced Tabular Data: A Comparative Study. Electronics. |
| [9] | Kizilcec RF, Lee H (2022) Algorithmic Fairness in Education. In: The Ethics of Artificial Intelligence in Education. Routledge. |
| [10] | Bhat J, Jayaram Y (2023) Predictive Analytics for Student Retention and Success Using AI/ML. IJAIDSML. |
| [11] | Tamada MM, Giusti R, Netto JFDM (2022) Predicting Students at Risk of Dropout in Technical Course Using LMS Logs. Electronics. |
| [12] | Pavletic K (2018) Educational Data Driven Decision Making: Early Identification of Students at Risk by Means of Machine Learning. Semantic Scholar. |
| [13] | Altaf S, Soomro W, Rawi MIM (2019) Student Performance Prediction using Multi-Layers ANN. ICISDM. |
| [14] | Adiyati N, Subekti R, et al (2025) Early Prediction of At Risk Students Using Minimal Data. Digitus. |
| [15] | Angeioplastis A, Aliprantis J, et al (2025) Predicting Student Performance Using Educational Data Mining Techniques. De Computis. |
| [16] | Karimi-Haghighi M, Castillo C (2021) Enhancing a recidivism prediction tool with ML: effectiveness and algorithmic fairness. ICAIL. |
| [17] | Zheng L (2025) Fairness verification algorithms and bias mitigation for AI criminal justice systems. JCMSE. |
| [18] | Goren O, Cohen L, Rubinstein A (2024) Early Prediction of Student Dropout in Higher Education Using ML. EDM 2024. |
| [19] | Alshaer F, Zeki A, Alzayed A (2025) Comparative Analysis of Data Mining Methods in University Admissions. IJCI. |
| [20] | Jaiswal G, Sharma A, Sarup R (2020) Machine Learning in Higher Education. Handbook of Research on Emerging Trends in ML. |
| [21] | Thaher T, Jayousi R (2020) Prediction of Student's Academic Performance using FNN Augmented with Stochastic Trainers. AICT. |
| [22] | Shi H, Zhang N, Caskurlu S, Na H (2025) Applications of ML for at-Risk Student Prediction in Online Education: A 10-Year Review. JCAL. |
| [23] | Wu J, Frías-Martínez V (2024) Improving the Fairness of Deep-Learning Crime Prediction with Under-reporting-aware Models. arXiv. |
| [24] | Wu J, Frías-Martínez E, Frías-Martínez V (2020) Addressing Under-Reporting to Enhance Fairness and Accuracy in Crime Prediction. SIGSPATIAL. |
| [25] | Farayola MM, Tal I, Saber T, et al (2025) A fairness-focused approach to recidivism prediction: implications for accuracy, trust, and equity. AI & SOCIETY. |
| [26] | Yusof Y, Fajila F (2026) Conditional Tabular GAN-based Synthetic Data Generation for Model Generalisation Improvement. JICT. |
| [27] | Stoian MC (2025) A Survey on Tabular Data Generation: Utility, Alignment, Fidelity, Privacy. arXiv. |
| [28] | Tanwar M, Srivastava R, et al (2025) AI-Driven Synthetic Data for Lung Cancer Prediction with TabDDPM and CTGAN. ICAAIC. |
| [29] | Dasu VA, Kumar A, Tizpaz-Niari S, Tan G (2024) NeuFair: Neural Network Fairness Repair with Dropout. ISSTA. |
| [30] | Nagaraj SKS (2025) An Analytical Framework for Bias Mitigation in Credit Scoring through Fairness-Constrained Neural Optimization. IJAIDSML. |
| [31] | Jain B, Huber M, Elmasri R (2024) Fairness for Deep Learning Using Bias Parity Score Based Loss Function Regularization. IJAIT. |
| [32] |
From prediction to parity: a quantitative analysis of algorithmic fairness in higher education. AI and Ethics.
https://link.springer.com/article/10.1007/s43681-025-00888-1 |
| [33] | Ngwu S. Data Subjects' Rights Under the Nigerian Data Protection Regulations 2019. Mondaq. |
| [34] |
Daniel F. NDPR Implementation Framework (November 2020). DataGuidance.
https://www.dataguidance.com/sites/default/files/ndpr_implementation_framework_november_2020.pdf |
| [35] | Xu L, Skoularidou M, Cuesta-Infante A, Veeramachaneni K (2019) Modeling Tabular data using Conditional GAN. NeurIPS. arXiv: 1907.00503. |
| [36] | Braunack-Mayer A, Street JM, Tooher R, et al (2020) Student and Staff Perspectives on the Use of Big Data in the Tertiary Education Sector. Review of Educational Research. |
| [37] | Azra H, Zeeshan I (2025) Harnessing Big Data Analytics in Education: Balancing Student Success with Privacy Concerns. SSRN. |
APA Style
Ogunyinka, T. K., Akinola, S. O., Adediran, E. A. (2026). A Multi-layer Perceptron Framework for Pre-admission Disciplinary Risk Prediction in Nigerian Universities: A Fairness-aware Approach Using Synthetic Data. International Journal of Engineering Management, 10(1), 1-13. https://doi.org/10.11648/j.ijem.20261001.11
ACS Style
Ogunyinka, T. K.; Akinola, S. O.; Adediran, E. A. A Multi-layer Perceptron Framework for Pre-admission Disciplinary Risk Prediction in Nigerian Universities: A Fairness-aware Approach Using Synthetic Data. Int. J. Eng. Manag. 2026, 10(1), 1-13. doi: 10.11648/j.ijem.20261001.11
@article{10.11648/j.ijem.20261001.11,
author = {Taiwo Kolawole Ogunyinka and Solomon Olalekan Akinola and Emmanuel Adebowale Adediran},
title = {A Multi-layer Perceptron Framework for Pre-admission Disciplinary Risk Prediction in Nigerian Universities:
A Fairness-aware Approach Using Synthetic Data},
journal = {International Journal of Engineering Management},
volume = {10},
number = {1},
pages = {1-13},
doi = {10.11648/j.ijem.20261001.11},
url = {https://doi.org/10.11648/j.ijem.20261001.11},
eprint = {https://article.sciencepublishinggroup.com/pdf/10.11648.j.ijem.20261001.11},
abstract = {Nigerian universities have long struggled to identify, before matriculation, which applicants are likely to become disciplinary problems on campus. Existing screening procedures are largely manual and reactive — problems surface after enrolment rather than at the gate. To close this gap, we built and tested a Multi-Layer Perceptron classifier that assigns each applicant a probabilistic risk score at the point of admission, giving institutional officers an evidence-based basis for early counselling and targeted resource deployment, well before misconduct occurs. Working with real student records was not feasible. Nigeria's data protection obligations impose strict constraints on profiling, and authentic admission data from universities was unavailable for this research. We therefore generated 5,000 synthetic applicant profiles using a Conditional Tabular GAN, a method purpose-built for datasets that mix continuous, ordinal, and categorical variables. Three statistical tests — the Kolmogorov–Smirnov statistic, Wasserstein distance, and Jensen–Shannon divergence — confirmed that the synthetic profiles reproduced the structural properties of realistic admission populations with high fidelity. Under five-fold stratified cross-validation, the MLP returned an accuracy of 0.841 ± 0.018, F1-score of 0.812 ± 0.021, and AUC-ROC of 0.891 ± 0.014, outperforming Logistic Regression, Random Forest, SVM, and XGBoost across all reported metrics. Two findings deserve particular attention. First, SHAP attribution analysis singled out prior disciplinary record and JAMB score as the variables driving predictions most strongly — a result with direct implications for what admissions officers should scrutinize. Second, the model treated applicants from different geopolitical zones unequally; an EOD of 0.078 across zones exceeded acceptable thresholds. Fairness-regularized retraining brought that Figure down to 0.043 with less than one percentage point of accuracy lost. To prevent the system from operating as a black box, a three-tier human-in-the-loop review protocol is proposed, and the entire deployment framework is mapped against Nigeria's National Data Protection Regulation and Data Protection Impact Assessment requirements.},
year = {2026}
}
TY - JOUR T1 - A Multi-layer Perceptron Framework for Pre-admission Disciplinary Risk Prediction in Nigerian Universities: A Fairness-aware Approach Using Synthetic Data AU - Taiwo Kolawole Ogunyinka AU - Solomon Olalekan Akinola AU - Emmanuel Adebowale Adediran Y1 - 2026/05/18 PY - 2026 N1 - https://doi.org/10.11648/j.ijem.20261001.11 DO - 10.11648/j.ijem.20261001.11 T2 - International Journal of Engineering Management JF - International Journal of Engineering Management JO - International Journal of Engineering Management SP - 1 EP - 13 PB - Science Publishing Group SN - 2640-1568 UR - https://doi.org/10.11648/j.ijem.20261001.11 AB - Nigerian universities have long struggled to identify, before matriculation, which applicants are likely to become disciplinary problems on campus. Existing screening procedures are largely manual and reactive — problems surface after enrolment rather than at the gate. To close this gap, we built and tested a Multi-Layer Perceptron classifier that assigns each applicant a probabilistic risk score at the point of admission, giving institutional officers an evidence-based basis for early counselling and targeted resource deployment, well before misconduct occurs. Working with real student records was not feasible. Nigeria's data protection obligations impose strict constraints on profiling, and authentic admission data from universities was unavailable for this research. We therefore generated 5,000 synthetic applicant profiles using a Conditional Tabular GAN, a method purpose-built for datasets that mix continuous, ordinal, and categorical variables. Three statistical tests — the Kolmogorov–Smirnov statistic, Wasserstein distance, and Jensen–Shannon divergence — confirmed that the synthetic profiles reproduced the structural properties of realistic admission populations with high fidelity. Under five-fold stratified cross-validation, the MLP returned an accuracy of 0.841 ± 0.018, F1-score of 0.812 ± 0.021, and AUC-ROC of 0.891 ± 0.014, outperforming Logistic Regression, Random Forest, SVM, and XGBoost across all reported metrics. Two findings deserve particular attention. First, SHAP attribution analysis singled out prior disciplinary record and JAMB score as the variables driving predictions most strongly — a result with direct implications for what admissions officers should scrutinize. Second, the model treated applicants from different geopolitical zones unequally; an EOD of 0.078 across zones exceeded acceptable thresholds. Fairness-regularized retraining brought that Figure down to 0.043 with less than one percentage point of accuracy lost. To prevent the system from operating as a black box, a three-tier human-in-the-loop review protocol is proposed, and the entire deployment framework is mapped against Nigeria's National Data Protection Regulation and Data Protection Impact Assessment requirements. VL - 10 IS - 1 ER -
Department of Computer Science, Gateway Polytechnic, Sapade, Nigeria
Department of Computer Science, University of Ibadan, Ibadan, Nigeria
Department of Computer Science, Lead City University, Ibadan, Nigeria

Figure 1. Proposed MLP-Based Disciplinary Risk Prediction Framework — Six-Stage Pipeline from Synthetic Data Generation to SHAP/LIME Explainability.
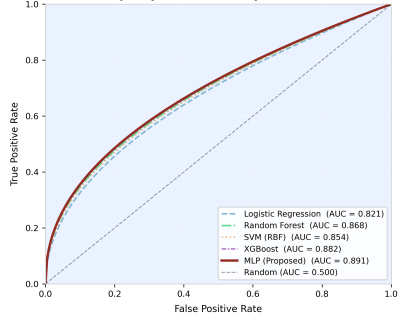
Figure 2. ROC Curves for All Five Evaluated Models — 5-Fold Stratified Cross-Validation. The MLP (red solid line) achieves the highest AUC-ROC (0.891).
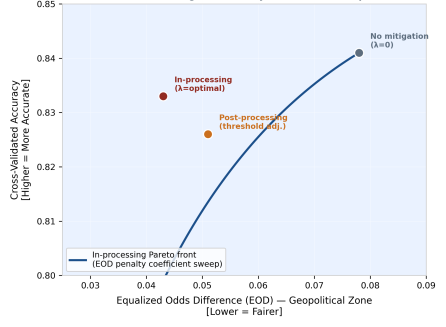
Figure 3. Fairness–Accuracy Pareto Front — In-Processing EOD Penalty Coefficient Sweep (Geopolitical Zone). Key operating points labelled: No mitigation (grey), Post-processing (orange), In-processing optimal (red).
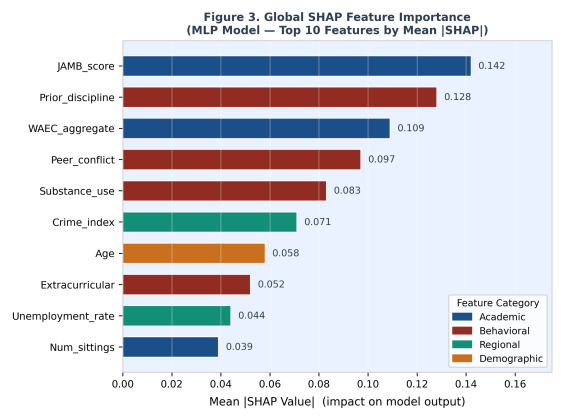
Figure 4. Global SHAP Feature Importance — Top 10 Features by Mean |SHAP| Value. Colours indicate feature category: Academic (blue), Behavioral (red), Regional (teal), Demographic (orange).
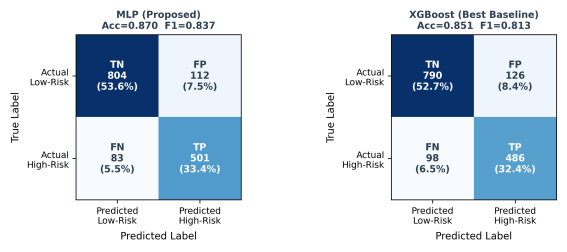
Figure 5. Confusion Matrices — MLP (Proposed) vs XGBoost (Best Baseline) on a Representative Test Fold (n = 1,500). TP = True Positive (correctly identified high-risk); TN = True Negative; FP = False Positive; FN = False Negative (missed high-risk).
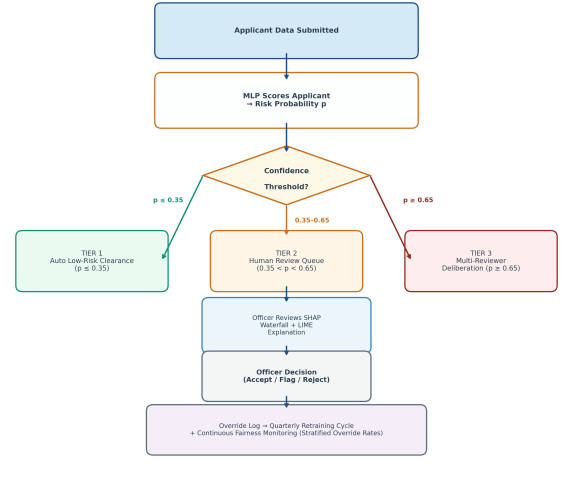
Figure 6. Three-Tier Human-in-the-Loop (HITL) Review Architecture for AI-Assisted Admissions Screening. Tier 1: automated clearance (p ≤ 0.35); Tier 2: human review with SHAP explanation (0.35 < p < 0.65); Tier 3: multi-reviewer deliberation (p ≥ 0.65). Override decisions feed back into quarterly model retraining.
Information

